近日,谷歌发布了一个高性能的实时手部追踪系统。不需要高性能的GPU、TPU,在手机上就能用!
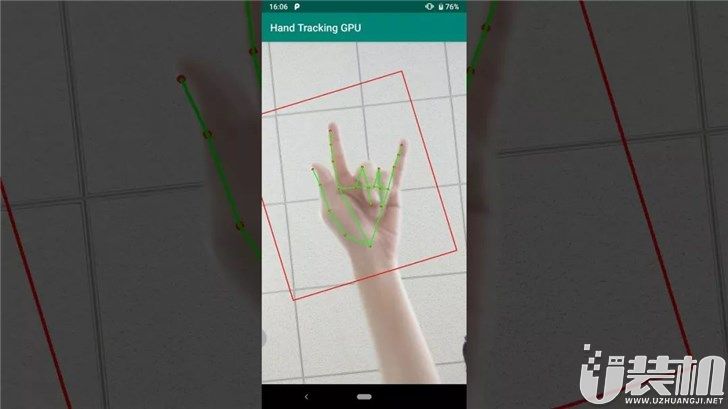
什么是手部追踪呢?来看一下下面这张动图就知道了。

通过MediaPipe在手机上实现实时3D手部捕捉
只要把你的手往镜头前一伸,该系统就可以通过使用机器学习(ML)从单个视频帧推断出手部的21个骨骼关键点(每根手指4个,手掌1个)的位置,从而得到高保真的手掌和手指运动追踪。
在此基础上,这一系统还可以推断出手势的含义。
虽然手部追踪这种能力是人类天生的,但是对计算机来说,能稳定地实时感知手部状态是一项极具挑战性的视觉任务。
难度来自多个方面。比如,双手的运动经常会导致某一部分被遮盖(例如合掌和握手),而手的颜色也没有很强的对比度。
同时,手部追踪也是各技术领域和应用平台上改善用户体验的关键技术之一。
比如说,手部形状识别是手语理解和手势控制的基础。它还可以在增强现实(AR)中将虚拟的数字内容叠加到真实的物理世界之上。
因此,谷歌这次的实时手部追踪意义重大。
事实上,谷歌已经在今年6月份的CVPR 2019会议上演示过该模型。而这一次,谷歌选择在MediaPipe这一个开源跨平台框架正式发布这一系统。
该系统背后的原理是什么呢?我们一起来看。
用于手部跟踪和手势识别的机器学习
谷歌的手部追踪方案使用了一个由多个模型协同工作组成的机器学习管道:
一个手掌探测器模型(BlazePalm),作用于整个图像并返回定向的手部边界框。
一个手部标志模型,作用于手掌探测器返回的裁剪图像区域,并返回高保真的3D手部关键点。
一个手势识别器,将先前得到的关键点排列分类为不同的手势。
这种架构类似于我们最近发布的面部网格ML管道以及其它用于姿势估计的架构。提供给手部标志模型的手掌剪裁图像大大降低了对额外数据(如旋转、平移和缩放)的要求,从而允许其将大部分能力用于针对坐标预测精度的处理。
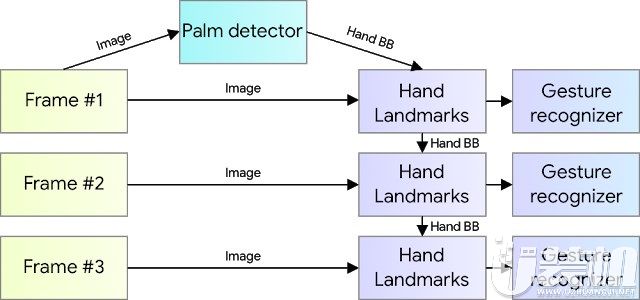
frame:帧;palm detector:手掌探测器;hand landmarks:手部标志模型;gesture recognizer:手势识别器
BlazePalm:实时手部/手掌探测
为了检测初始手部位置,我们采用名为BlazePalm的单发探测器模型,它参考了MediaPipe中的BlazeFace,并进行了优化以针对实时移动应用。
检测人手是一项非常复杂的任务:我们的模型必须适用于各种尺寸的手掌,还要能够检测各种遮挡和合掌的情况。
面部具有眼睛和嘴巴这样的高对比度特征,手部却没有。因此,机器学习模型通常很难仅靠视觉特征来进行准确检测。但如能提供额外的环境信息,如手臂、身体或人物等特征等,则有助于手部的精确定位。
在我们的方法中使用了不同的策略来解决上述挑战。首先,我们训练的是手掌探测器而非手部探测器,因为检测像手掌和拳头这样的刚性物体的边界比检测整个手部要简单得多。此外,由于手掌的面积较小,这使得非极大值抑制算法在双手遮挡情况(如握手)下也能得到良好结果;手掌可以使用方形边界框(也就是ML术语中的anchors)来描述,忽略其长宽比,从而可将anchors的数量减少3-5倍。其次,编码-解码特征提取器可用于在更大范围的环境中感知很小的物体(类似于RetinaNet方法)。最后,我们将训练期间的焦点损失(focal loss)降至最低,用以支持由于高尺度方差而产生的大量anchors。
利用上述技术,我们在手掌检测中得到了95.7%的平均精度。而使用固定的交叉熵损失且没有解码器的情况下精度基准仅为86.22%。
手部标志模型
在对整个图像进行手掌检测之后,手部标志模型通过回归(即直接坐标预测)在之前检测到的手部区域内精确定位了21个3D手部骨骼关键点坐标。这个模型学习了连续的手势图案,并且对于被遮挡只有部分可见的手部也能识别。
为了获得可靠数据,我们手动标注了大约30000幅具有手部骨骼关键点坐标的真实图像,如下所示(我们从图像深度图中获取Z值,如果它相应的坐标存在)。为了更好地覆盖可能的手部姿势并对手部几何形状的性质提供额外的比照,我们还在各种背景下渲染高质量的合成手部模型,并将其映射到相应的3D坐标。

上图:传给跟踪网络的带标注的校准手势图下图:带标注的渲染合成手部图像
然而,纯粹的合成数据很难泛化应用到新的数据集上。为了解决这个问题,我们使用混合训练模式。下图显示了大概的模型训练流程。
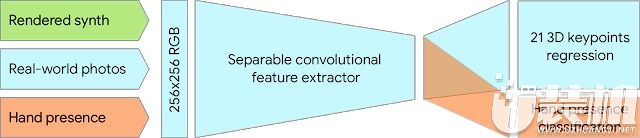
Rendered synth:渲染合成图片;real-world photos:真实图像;hand presence:手部图片;separable convolutional festure extractor:可分离卷积特征提取;21 3Dkeypoints regression:21个3D关键点回归;hand presence classification:手部分类手部跟踪网络的混合训练模式,裁剪的真实图像和渲染的合成图像用作预测21个3D关键点的输入数据
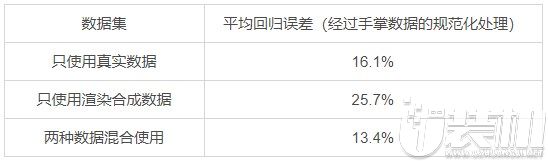
下表总结了基于训练数据性质的回归准确率。综合使用合成数据和真实数据可显著提升性能。

手势识别
基于预测出来的手部骨骼,我们用一个简单的算法来推导手势含义。首先,每个手指的状态(如弯曲或笔直等)由多个关节的累积弯曲角度决定。然后我们将手指状态集映射到一组预定义的手势集合上。这种简单却有效的技术使我们能够精确地估计基本的静态手势。现有的机器学习管道支持识别不同国家的姿势(如美国、欧洲和中国),还支持各种手势含义,包括“拇指向上”、“握拳”、“OK”、“摇滚”和“蜘蛛侠”等。
MediaPipe实现
谷歌的手部跟踪MediaPipe模型图如下所示。该图由两个子图组成,一个用于手部检测,一个用于手部骨骼关键点(标志点)计算。
MediaPipe的一个关键优化是手掌探测器仅在必要时(很少)运行,从而节省了大量的计算时间。
MediaPipe地址:
https://mediapipe.dev
GitHub地址:
https://github.com/google/mediapipe
MediaPipe利用MediaPipe,可以将感知管道构建为模块化组件的图形,包括例如推理模型(例如,TensorFlow,TFLite)和媒体处理功能。
谷歌在上周也将这一平台进行了开源,适配多种视觉检测任务。目前在GitHub上星标已经达到了2k+。
通过从当前帧中计算手部关键点推断后续视频帧中的手部位置来实现这一点,从而不必在每个帧上都运行手掌检测器。为了得到稳定结果,手部探测器模型会输出一个额外的标量,用于表示手是否存在于输入图像中并姿态合理的置信度。只有当置信度低于某个阈值时,手部探测器模型才会重新检测整个帧。

Realtimeflowlimiter:实时限流器;handdetection:手部探测;detectiontorectangle:检测到矩形;image cropping:图像裁剪;handlandmark:手部标志;landmarktorectangle:标志成矩形;annotationrender:注释渲染手部标志模型的输出(REJECT_HAND_FLAG)控制何时触发手部检测模型。这种行为是通过MediaPipe强大的同步构建块实现的,从而实现ML管道的高性能和最佳吞吐量。
高效的ML解决方案可以实时并在各种不同的平台和外形上运行,但与上述简化描述相比,其具有更高的复杂性。最后,谷歌在MediaPipe框架中将上述手部跟踪和手势识别管道开源,并附带相关的端到端使用场景和源代码。
链接如下:
https://github.com/google/mediapipe/blob/master/mediapipe/docs/hand_tracking_mobile_gpu.md
这为研究和开发人员提供了完整的可用于实验的程序栈,可以基于谷歌的模型来对新想法进行原型设计。
未来方向
谷歌称,未来计划通过更强大和稳定的跟踪锁定方法扩展此技术,来扩大能可靠检测的手势数量,并支持实时变化的动态手势检测。
相信这项技术的开源也可以促使研究和开发者社区产生大量的创意和应用!





优装机下载站(https://www.uzhuangji.net/)版权所有(网站邮箱:gua_niu66@163.com)陕ICP备2024030148号-1
本站资源均收集整理于互联网,其著作权归原作者所有,如果有侵犯您权利的资源,请来信告知,我们将及时撤销相应资源。

 下载
下载




















